


Animaj, a next-generation kids’ media company, unveils its new AI tool, "Sketch-to-Motion", at Web Summit 2024 in Lisbon.
This technology is set to transform the animation industry by taking what once took weeks, if not months, and making it happen instantly—turning rough sketches into fully-rendered 3D animations with one click.
The Motivation: limitations of Motion Capture
Building on our previous work integrating motion capture technology into our 3D animation production workflow, we discovered both the power and limitations of motion-to-motion techniques in animation.
While motion capture excels at capturing lifelike movements, certain animation styles demand a different approach. In Pocoyo, for example, each character has its own distinct way of moving, striking exaggerated, iconic poses with snappy movements—far from the natural flow of human actors. Capturing human performance for such animations is suboptimal, as it requires extensive tweaking by animators to fit the iconic poses and snappy animation style.
On the other hand, animatics—essentially animated storyboards with sequences of sketches played back-to-back—are better suited to create Pocoyo's snappy, iconic motion.
Motivated by these challenges, we set out to develop an AI model that could transform animatics into stylized 3D poses, speeding up the workflow without sacrificing the animation's unique style or quality.

The Project: Sketch-to-Motion
The primary goal of Sketch-to-Motion is to automate parts of the animation process, reducing manual work and repetitive tasks of low added value, especially in transforming animatics into 3D character poses. The objective is to convert a series of artist sketches into a complete animation.
The project is divided into two distinct tasks, each tackled by a specific model:
- The Sketch-to-Pose Model: This model takes a storyboard artist's drawing of a character in a specific pose as input and outputs the character's 3D pose as a rig, predicting the values of the character's skeletal controllers. These controllers include elements like head rotation, hand positions, and elbow orientations. This rig can be represented as a numerical vector. Essentially, the sketch-to-pose model functions as a neural network that predicts this numerical vector from an image.
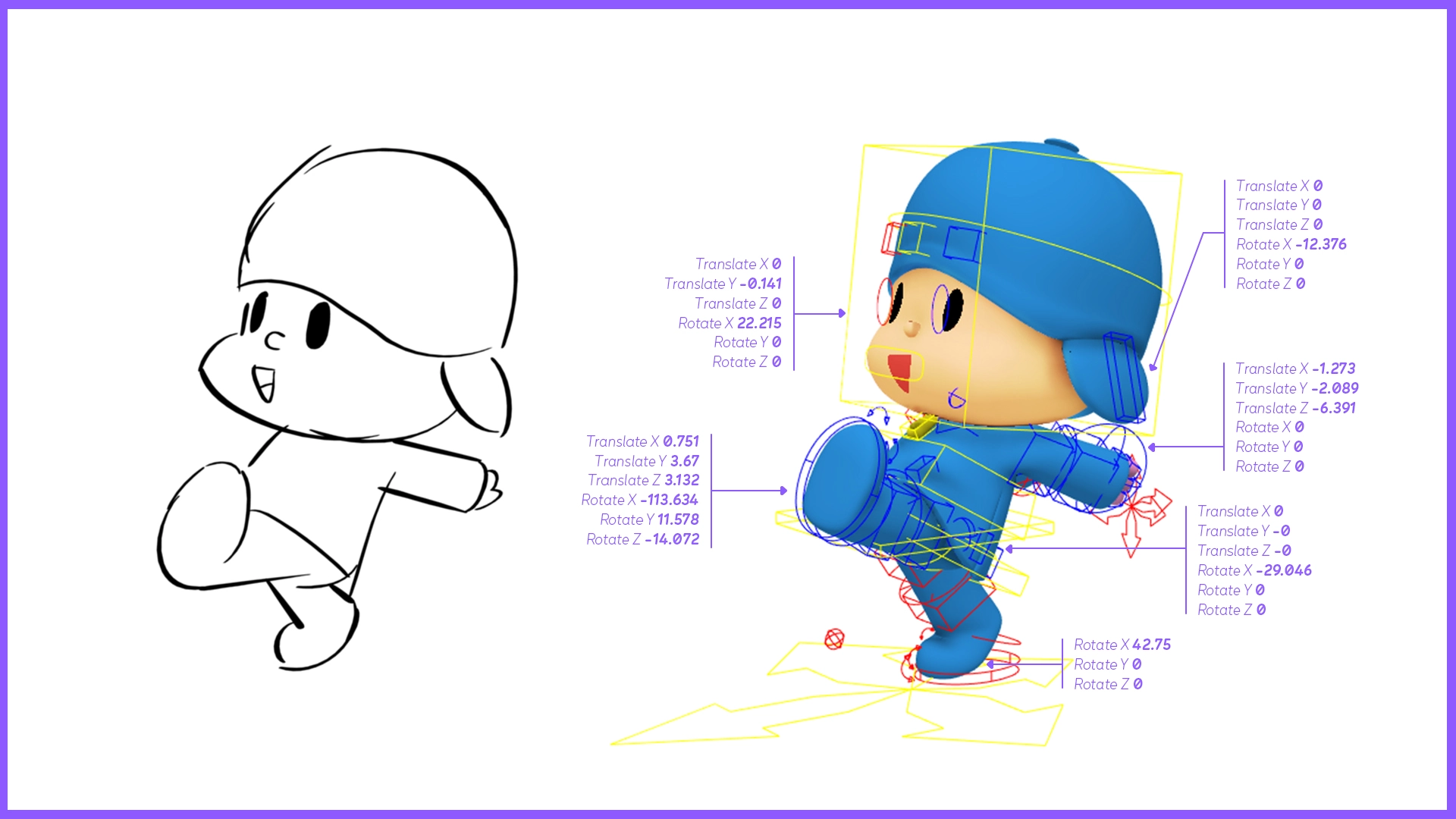
- The Motion In-Betweening Model: This model takes the sequence of predicted poses as input and transforms it into a complete motion that preserves the character's unique motion style and rhythm.
This article will focus on presenting the Sketch-to-Pose model, while the Motion In-Betweening model will be covered in a separate article.
The Data: obtaining pairs of sketches and poses
The most effective way to train neural networks is through supervised learning, which relies on paired data. For our project, we needed pairs of character sketches and their corresponding 3D poses. Fortunately, we had access to four full seasons of Pocoyo, with each animation scene accompanied by animatics drawn by a storyboard artist. By leveraging these assets, we were able to compile a dataset of over 300,000 unique poses paired with sketches in various styles.
To capture the specific drawing style of the storyboard artists who will be creating the animatics for the upcoming season of Pocoyo, we also asked these artists to produce additional sketches based on given poses, which we then added to the final dataset.
The Model: designing an image-to-vector model
Once we had the data, we designed a deep learning model to transform sketches into pose vectors. Initially, we focused on Convolutional Neural Networks (CNNs) due to their strong ability to encode images into vectorized representations. CNNs are particularly well-suited for analyzing sketches and extracting diverse features from distinct drawn body parts. We also explored more complex models, including a diffusion model inspired by the state-of-the-art Motion Diffusion Model. While this model performed comparably to the CNN baseline, its slower inference time led us to prefer the simpler CNN-based approach.
The Metric: evaluating controller prediction distance and rendering fidelity
To evaluate performance, compare different models, and select the best hyperparameters, we needed a clear quantitative metric. We initially designed a simple one: the Mean Absolute Error (MAE) between the predicted controllers and the ground truth controllers. This metric has the advantage of being easy to compute and allows us to assess how accurately each controller is predicted.
The main drawback is that it treats each controller equally, even though some controllers are more important because they control larger parts of the body, unlike more localized controllers. To account for the visual importance of each controller, we developed an image-based metric that measures the pixel-space distance between the rendering of the predicted pose and the rendering of the ground truth pose.
The Experiments: finding the best hyperparameters
Using these two complementary metrics, we iterated on various aspects of the models, data, and optimization parameters to improve performance:
- Model Architectures: We tested multiple backbone architectures for the image encoder.
- Final Projection Layer: We experimented with the size of the final projection layer, its activation function, and dropout level.
- Loss Functions: For rig vector prediction, we compared several loss functions: MSE, L1, and SmoothL1. Additionally, we applied weights to each controller to account for their relative importance in the overall skeleton structure.
- Optimization: We identified the best optimization parameters, including batch size, learning rate, and scheduler settings.
- Data: We explored various datasets and data augmentation techniques, such as image cropping, padding, rotation, and translation.
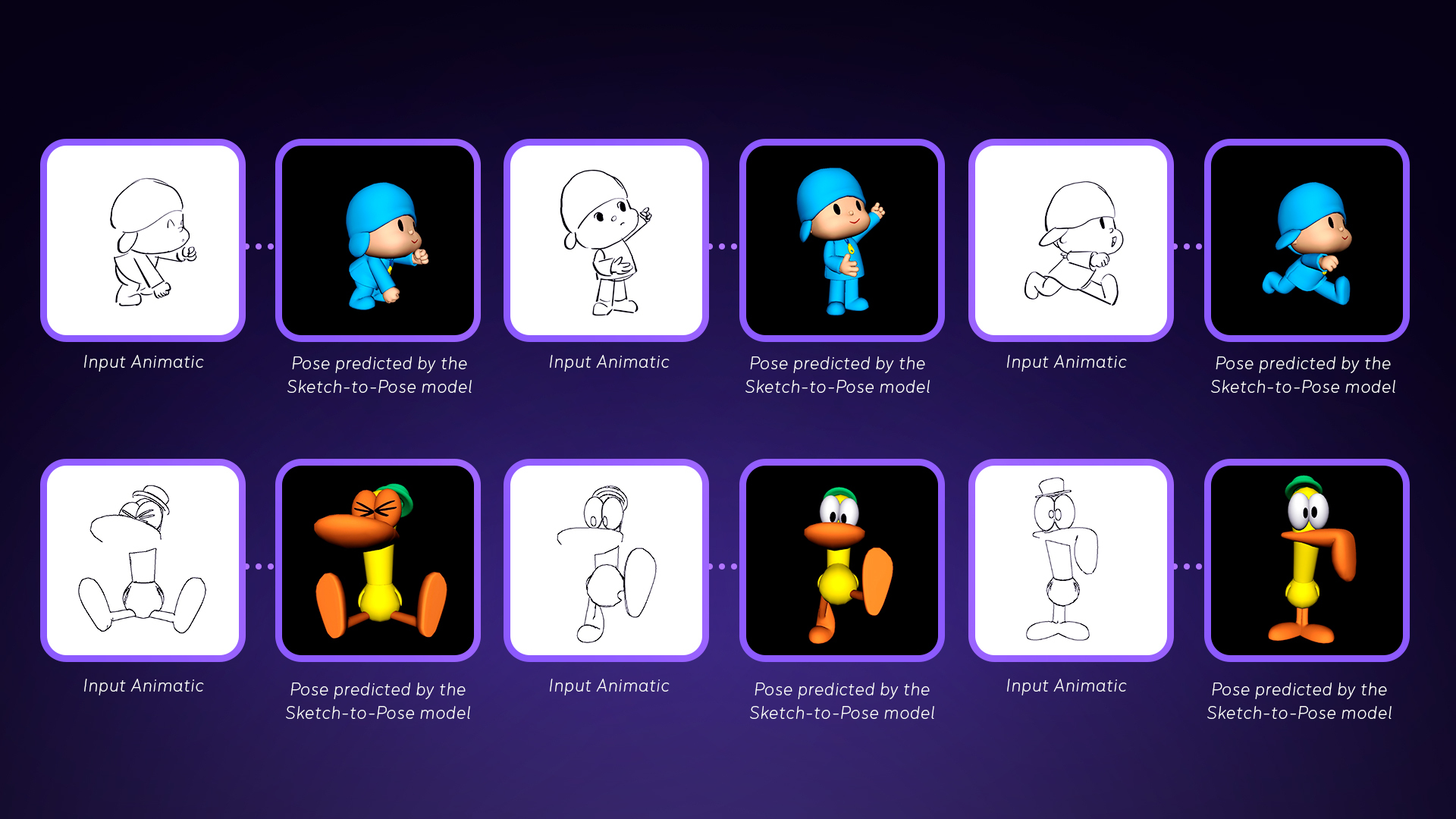
The Results: final sketch-to-pose model
Here are some examples of images generated by the best sketch-to-pose model:
The Test in production: comparing our sketch-to-pose model with the traditional workflow
We asked a 3D animator to create a 2-minute animation of Pocoyo from an animatic using two different methods. First, he used the traditional animation workflow, fully animating the character by hand. In the second test, we input the animatic into our sketch-to-pose model, allowing the animator to make corrections to the generated animation.
With the traditional workflow, creating the 2-minute animation took him more than 14 hours. In contrast, using our sketch-to-pose model reduced the time required to just above 6 hours. This represents a significant time-saving achievement, especially considering that creating key poses is a labor-intensive step in the animation pipeline. This reduction allows animators to concentrate more on refining the style and flow of scenes rather than starting from scratch with each new pose.

Conclusion: The Future of AI in Animation
With our Sketch-to-Pose model, we’ve taken a big step forward in simplifying the process of creating key poses in animation. However, setting up key poses is only part of the challenge. The next major hurdle lies in “Motion In-Betweening” — filling in the frames between key poses to achieve snappy, style-consistent transitions that respect the unique animation aesthetic. In our next article, we’ll delve into how we tackle this new challenge. Our goal is to further streamline the animation workflow, enabling animators to bring characters to life faster than ever before.
In blending AI with animation, we’re starting to see how technology can empower artists, giving them more time to focus on creativity while automating the repetitive tasks. As we move forward, projects like sketch-to-motion will open new doors, making it easier to bring imaginative worlds like Pocoyo to life in even more efficient and expressive ways.

.svg)



.webp)
.webp)




